






構(gòu)建云原生數(shù)據(jù)倉庫和數(shù)據(jù)湖的最佳實(shí)踐
以下探索一下通過數(shù)據(jù)倉庫、數(shù)據(jù)湖、數(shù)據(jù)流和湖屋構(gòu)建原生云數(shù)據(jù)分析基礎(chǔ)設(shè)施的經(jīng)驗(yàn)和教訓(xùn):
教訓(xùn)1:在正確的地方處理和存儲(chǔ)數(shù)據(jù)
首先要問問自己:數(shù)據(jù)的用例是什么?
以下是一些數(shù)據(jù)用例示例和實(shí)現(xiàn)業(yè)務(wù)用例的示例工具:
·管理循環(huán)報(bào)告=>數(shù)據(jù)倉庫及其開箱即用的報(bào)告工具。
·結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)的交互式分析=>數(shù)據(jù)倉庫或其他數(shù)據(jù)存儲(chǔ)之上的商業(yè)智能工具,如Tableau、Power BI、Qlik或TIBCO Spotfire。
·事務(wù)性業(yè)務(wù)負(fù)載=>在Kubernetes環(huán)境或無服務(wù)器云基礎(chǔ)設(shè)施中運(yùn)行的自定義Java應(yīng)用程序。
·高級分析,以了解歷史數(shù)據(jù)=>存儲(chǔ)在數(shù)據(jù)池中的原始數(shù)據(jù)集,用于應(yīng)用強(qiáng)大的人工智能/機(jī)器學(xué)習(xí)技術(shù)(如TensorFlow)算法。
·新事件的實(shí)時(shí)操作=>流式應(yīng)用程序在相關(guān)數(shù)據(jù)時(shí)連續(xù)處理和關(guān)聯(lián)數(shù)據(jù)。
(1)根據(jù)需要在正確的平臺(tái)上進(jìn)行實(shí)時(shí)或批量計(jì)算
批處理工作負(fù)載在為此而構(gòu)建的基礎(chǔ)設(shè)施中運(yùn)行得最好。例如,Hadoop或ApacheSpark。實(shí)時(shí)工作負(fù)載在為此而構(gòu)建的基礎(chǔ)設(shè)施中運(yùn)行得最好。例如ApacheKafka。
然而,有時(shí)兩個(gè)平臺(tái)都可以使用。了解底層基礎(chǔ)設(shè)施,以最佳方式利用它。Apache Kafka可以替換一個(gè)數(shù)據(jù)庫!盡管如此,它應(yīng)該只在少數(shù)有意義的場景中進(jìn)行(例如,簡化架構(gòu)或增加業(yè)務(wù)價(jià)值)。
例如,作為事件序列的可重播性(帶有時(shí)間戳的保證順序)內(nèi)置于不可變的Kafka日志中。從Kafka中重放和重新處理歷史數(shù)據(jù)是很直接的,也是很多場景的完美用例,其中包括:
·新的消費(fèi)者應(yīng)用程序
·錯(cuò)誤處理
·合規(guī)/法規(guī)處理
·查詢和分析已有事件
·分析平臺(tái)的模式變化
·模型訓(xùn)練
另一方面,如果需要進(jìn)行復(fù)雜的分析,如映射減少或變換、具有數(shù)十個(gè)join的SQL查詢、傳感器事件的健壯時(shí)間序列分析、基于攝取日志信息的搜索索引,等等。然后,最好選擇Spark、Rockset、ApacheDruid或Elasticsearch作為用例。
(2)使用云原生對象存儲(chǔ)實(shí)現(xiàn)分層存儲(chǔ)以提高效率并降低成本
單個(gè)存儲(chǔ)基礎(chǔ)設(shè)施無法解決所有這些問題。因此,在上述用例中,將所有數(shù)據(jù)攝取到單個(gè)系統(tǒng)將無法成功。因此需要選擇最好的方法。
現(xiàn)代的原生云系統(tǒng)將存儲(chǔ)和計(jì)算分離開來。對于數(shù)據(jù)流平臺(tái)(如Apache Kafka)和分析平臺(tái)(如Apache Spark、Snowflake或谷歌Big Query)來說也是如此。SaaS解決方案實(shí)現(xiàn)了創(chuàng)新的分層存儲(chǔ)解決方案(隱藏在內(nèi)部,所以看不到它們,從而實(shí)現(xiàn)了存儲(chǔ)和計(jì)算之間的低成本分離。
現(xiàn)代數(shù)據(jù)流服務(wù)也利用了分級存儲(chǔ)。
第二個(gè)教訓(xùn):不要為靜止數(shù)據(jù)進(jìn)行反向設(shè)計(jì)
問問自己:如果現(xiàn)在而不是以后處理數(shù)據(jù)(不管以后意味著什么),是否有任何額外的業(yè)務(wù)價(jià)值?
如果是,那么第一步不要將數(shù)據(jù)存儲(chǔ)在數(shù)據(jù)庫、數(shù)據(jù)湖或數(shù)據(jù)倉庫中。數(shù)據(jù)在靜止?fàn)顟B(tài)下存儲(chǔ),不再用于實(shí)時(shí)處理。如果在用例中實(shí)時(shí)數(shù)據(jù)優(yōu)于慢速數(shù)據(jù),那么像Apache Kafka這樣的數(shù)據(jù)流平臺(tái)是正確的選擇!
研究發(fā)現(xiàn),很多人把他們所有的原始數(shù)據(jù)放入數(shù)據(jù)存儲(chǔ)中,只是為了發(fā)現(xiàn)他們可以在以后實(shí)時(shí)利用這些數(shù)據(jù)。然后,在啟動(dòng)反向ETL工具后,通過變更數(shù)據(jù)捕獲(CDC)或類似方法再次訪問數(shù)制湖中的數(shù)據(jù)?;蛘?,如果使用Spark Structured Streaming(=“real-time”),但獲取“實(shí)時(shí)流處理”數(shù)據(jù)的第一件事是從S3對象存儲(chǔ)中讀取數(shù)據(jù)(=“at rest and too later”)是不合適的。
(1)反向ETL不是實(shí)時(shí)用例的正確方法
如果將數(shù)據(jù)存儲(chǔ)在數(shù)據(jù)倉庫或數(shù)據(jù)湖中,則無法再實(shí)時(shí)處理數(shù)據(jù),因?yàn)樗呀?jīng)在靜止?fàn)顟B(tài)下存儲(chǔ)。這些數(shù)據(jù)存儲(chǔ)是為索引、搜索、批處理、報(bào)告、模型培訓(xùn)以及存儲(chǔ)系統(tǒng)中有意義的其他使用案例而構(gòu)建的。但是,不能從靜態(tài)存儲(chǔ)中實(shí)時(shí)處理動(dòng)態(tài)數(shù)據(jù)。
(2)數(shù)據(jù)流是為實(shí)時(shí)連續(xù)處理數(shù)據(jù)而構(gòu)建的
這就是事件流發(fā)揮作用的地方。像Apache Kafka這樣的平臺(tái)支持實(shí)時(shí)處理事務(wù)和分析工作負(fù)載的動(dòng)態(tài)數(shù)據(jù)。
在現(xiàn)代事件驅(qū)動(dòng)架構(gòu)中不需要反向ETL!它“內(nèi)置”到開箱即用的架構(gòu)中。如果適當(dāng)且技術(shù)上可行,每個(gè)使用者直接實(shí)時(shí)使用數(shù)據(jù)。數(shù)據(jù)倉庫或數(shù)據(jù)湖仍然以接近實(shí)時(shí)或批量的速度處理數(shù)據(jù)。
同樣,這并不意味著不應(yīng)該將數(shù)據(jù)放在數(shù)據(jù)倉庫或數(shù)據(jù)湖中。但只有在以后需要分析數(shù)據(jù)時(shí)才這樣做。靜態(tài)數(shù)據(jù)存儲(chǔ)不適合實(shí)時(shí)工作。
教訓(xùn)3:不需要Lambda架構(gòu)來分離批處理和實(shí)時(shí)工作負(fù)載
問問自己:用最喜歡的數(shù)據(jù)分析技術(shù)消費(fèi)和處理傳入數(shù)據(jù)的最簡單方法是什么?
(1)實(shí)時(shí)數(shù)據(jù)勝過慢數(shù)據(jù),但并不總是如此
考慮所在的行業(yè)、業(yè)務(wù)單位、解決的問題以及構(gòu)建的創(chuàng)新應(yīng)用程序。實(shí)時(shí)數(shù)據(jù)勝過慢數(shù)據(jù)。這種說法幾乎總是正確的。或者增加收入,降低成本,降低風(fēng)險(xiǎn),或者改善客戶體驗(yàn)。
靜態(tài)數(shù)據(jù)意味著將數(shù)據(jù)存儲(chǔ)在數(shù)據(jù)庫、數(shù)據(jù)倉庫或數(shù)據(jù)湖中。這樣,即使實(shí)時(shí)流組件(如Kafka)接收數(shù)據(jù),數(shù)據(jù)在許多用例中處理得太晚。數(shù)據(jù)處理仍然是一個(gè)Web服務(wù)調(diào)用、SQL查詢或map-reduce批處理過程,無法為問題提供結(jié)果。
靜止的數(shù)據(jù)并不是一件壞事。有幾個(gè)用例都可以很好地使用這種方法,例如報(bào)告(業(yè)務(wù)智能)、分析(批處理)和模型訓(xùn)練(機(jī)器學(xué)習(xí)) 。但在幾乎所有其他用例中,實(shí)時(shí)性能優(yōu)于批處理。
(2)Kappa架構(gòu)簡化了批處理和實(shí)時(shí)工作負(fù)載的基礎(chǔ)設(shè)施
Kappa架構(gòu)是一個(gè)基于事件的軟件架構(gòu),可以實(shí)時(shí)處理事務(wù)和分析工作負(fù)載的任何規(guī)模的所有數(shù)據(jù)。
Kappa架構(gòu)背后的核心前提是,可以使用單個(gè)技術(shù)堆棧執(zhí)行實(shí)時(shí)處理和批處理。這是一種與眾所周知的Lambda架構(gòu)截然不同的方法。后者將批處理工作負(fù)載和實(shí)時(shí)工作負(fù)載分離到單獨(dú)的基礎(chǔ)設(shè)施和技術(shù)堆棧中。
Kappa基礎(chǔ)設(shè)施的核心是流式結(jié)構(gòu)。首先,事件流平臺(tái)日志存儲(chǔ)傳入數(shù)據(jù)。從那里,流處理引擎可以持續(xù)實(shí)時(shí)地處理數(shù)據(jù),或者通過任何通信范式和速度(包括實(shí)時(shí)、近實(shí)時(shí)、批處理和請求響應(yīng))將數(shù)據(jù)攝入任何其他分析數(shù)據(jù)庫或業(yè)務(wù)應(yīng)用程序。
教訓(xùn)4:理解靜態(tài)數(shù)據(jù)共享和流數(shù)據(jù)交換之間的權(quán)衡
問問自己:需要如何與其他內(nèi)部業(yè)務(wù)單位或外部企業(yè)共享數(shù)據(jù)?
(1)使用數(shù)據(jù)流、數(shù)據(jù)湖、數(shù)據(jù)倉庫和數(shù)據(jù)湖屋進(jìn)行混合和多云復(fù)制的用例
跨數(shù)據(jù)中心、區(qū)域或云計(jì)算提供商復(fù)制數(shù)據(jù)有很多理由:
•災(zāi)難恢復(fù)和高可用性:創(chuàng)建災(zāi)難恢復(fù)集群,并在業(yè)務(wù)中斷時(shí)時(shí)進(jìn)行故障轉(zhuǎn)移。
·全球和多云復(fù)制:跨區(qū)域和云計(jì)算移動(dòng)和聚合數(shù)據(jù)。
·數(shù)據(jù)共享:與其他團(tuán)隊(duì)、業(yè)務(wù)線或企業(yè)共享數(shù)據(jù)。
·數(shù)據(jù)遷移:將數(shù)據(jù)和工作負(fù)載從一個(gè)集群遷移到另一個(gè)集群(就像從傳統(tǒng)的內(nèi)部部署數(shù)據(jù)倉庫遷移到云原生數(shù)據(jù)湖屋)。
(2)實(shí)時(shí)數(shù)據(jù)復(fù)制勝過慢速數(shù)據(jù)共享
圍繞內(nèi)部或外部數(shù)據(jù)共享的故事與其他應(yīng)用程序并無不同。實(shí)時(shí)復(fù)制勝過緩慢的數(shù)據(jù)交換。因此,如果實(shí)時(shí)信息增加了業(yè)務(wù)價(jià)值,那么靜態(tài)存儲(chǔ)數(shù)據(jù)然后將其復(fù)制到另一個(gè)數(shù)據(jù)中心、區(qū)域或云提供者是一種反模式。
以下示例顯示了獨(dú)立利益相關(guān)者(即不同企業(yè)中的域)如何使用跨公司流數(shù)據(jù)交換:
創(chuàng)新不會(huì)止步于自己的邊界。流復(fù)制適用于實(shí)時(shí)數(shù)據(jù)優(yōu)于慢速數(shù)據(jù)的所有用例(適用于大多數(shù)場景)。舉幾個(gè)例子:
(3)從供應(yīng)商到制造商到中間商再到售后的端到端供應(yīng)鏈優(yōu)化
·跨越國家的追蹤。
·將第三方附加服務(wù)集成到自己的數(shù)字產(chǎn)品中。
·開放API,用于嵌入和組合外部服務(wù),以構(gòu)建新產(chǎn)品。
另外,要理解為什么API(=REST/HTTP)和數(shù)據(jù)流(=Apache Kafka)是互補(bǔ)關(guān)系,而不是競爭關(guān)系。
教訓(xùn)5:數(shù)據(jù)網(wǎng)格不是單一的產(chǎn)品或技術(shù)
問問自己:如何創(chuàng)建一個(gè)靈活和敏捷的企業(yè)架構(gòu)來更有效地創(chuàng)新,并更快地解決業(yè)務(wù)問題?
(1)數(shù)據(jù)網(wǎng)格是邏輯視圖,而不是物理視圖
數(shù)據(jù)網(wǎng)格轉(zhuǎn)變?yōu)橐环N借鑒現(xiàn)代分布式架構(gòu)的范式:將域視為首要關(guān)注點(diǎn),應(yīng)用平臺(tái)思維創(chuàng)建自助式數(shù)據(jù)基礎(chǔ)設(shè)施,將數(shù)據(jù)視為產(chǎn)品,并實(shí)現(xiàn)開放標(biāo)準(zhǔn)化以實(shí)現(xiàn)可互操作的分布式數(shù)據(jù)產(chǎn)品生態(tài)系統(tǒng)。
下面是一個(gè)數(shù)據(jù)網(wǎng)格的例子:
數(shù)據(jù)網(wǎng)格結(jié)合了現(xiàn)有的范式,包括領(lǐng)域驅(qū)動(dòng)設(shè)計(jì)、數(shù)據(jù)集市、微服務(wù)和事件流。
(2)數(shù)據(jù)倉庫或數(shù)據(jù)湖不是也不可能成為整個(gè)數(shù)據(jù)網(wǎng)格
數(shù)據(jù)網(wǎng)格基礎(chǔ)設(shè)施的核心應(yīng)該是實(shí)時(shí)的、解耦的、可靠的和可伸縮的。Kafka是一個(gè)現(xiàn)代的云原生企業(yè)集成平臺(tái)(如今也常稱為iPaaS)。因此,Kafka為數(shù)據(jù)網(wǎng)格的基礎(chǔ)提供了所有的功能。
然而,并不是所有的組件都可以或者應(yīng)該是基于kafka的。微服務(wù)架構(gòu)的美妙之處在于,每個(gè)應(yīng)用程序都可以選擇正確的技術(shù)。一個(gè)應(yīng)用程序可能包含也可能不包含數(shù)據(jù)庫、分析工具或其他補(bǔ)充組件。數(shù)據(jù)產(chǎn)品的輸入和輸出數(shù)據(jù)端口應(yīng)獨(dú)立于所選解決方案:
Kafka可以成為云原生數(shù)據(jù)網(wǎng)格的一個(gè)戰(zhàn)略組件。但是,即使不使用數(shù)據(jù)流,只使用靜止數(shù)據(jù)構(gòu)建數(shù)據(jù)網(wǎng)格,也沒有什么靈丹妙藥。不要試圖用單一的產(chǎn)品、技術(shù)或供應(yīng)商構(gòu)建一個(gè)數(shù)據(jù)網(wǎng)格。無論該工具是專注于實(shí)時(shí)數(shù)據(jù)流、批處理和分析,還是基于API的接口。Starburst是一個(gè)基于SQL的MPP查詢引擎,由開源Trino(前身為Presto)提供支持,支持對不同數(shù)據(jù)存儲(chǔ)進(jìn)行分析。
(3)云原生數(shù)據(jù)倉庫的最佳實(shí)踐超越SaaS產(chǎn)品
構(gòu)建原生云數(shù)據(jù)倉庫或數(shù)據(jù)湖是一個(gè)龐大的項(xiàng)目。它需要數(shù)據(jù)攝入、數(shù)據(jù)集成、與分析平臺(tái)的連接、數(shù)據(jù)隱私和安全模式等等。在報(bào)告或分析等實(shí)際任務(wù)開始之前,所有這些都是必需的。
超出數(shù)據(jù)倉庫或數(shù)據(jù)湖范圍的完整企業(yè)架構(gòu)甚至更加復(fù)雜。必須應(yīng)用最佳實(shí)踐來構(gòu)建一個(gè)有彈性的、可擴(kuò)展、彈性的和具有成本效益的數(shù)據(jù)分析基礎(chǔ)設(shè)施。服務(wù)等級協(xié)議(SLA)、延遲和正常運(yùn)行時(shí)間在業(yè)務(wù)域中有非常不同的需求。最好的方法是為工作選擇合適的工具。業(yè)務(wù)單元和應(yīng)用程序之間的真正解耦允許專注于解決特定的業(yè)務(wù)問題。
存儲(chǔ)和計(jì)算分離,統(tǒng)一的實(shí)時(shí)管道而不是批處理和實(shí)時(shí)分離,避免像反向ETL這樣的反模式,適當(dāng)?shù)臄?shù)據(jù)共享概念使云原生數(shù)據(jù)分析成為可能。
關(guān)于企業(yè)網(wǎng)D1net(m.r5u5c.cn):
國內(nèi)主流的to B IT門戶,同時(shí)在運(yùn)營國內(nèi)最大的甲方CIO專家?guī)旌椭橇敵黾吧缃黄脚_(tái)-信眾智(www.cioall.com)。同時(shí)運(yùn)營18個(gè)IT行業(yè)公眾號(微信搜索D1net即可關(guān)注)。
版權(quán)聲明:本文為企業(yè)網(wǎng)D1Net編譯,轉(zhuǎn)載需注明出處為:企業(yè)網(wǎng)D1Net,如果不注明出處,企業(yè)網(wǎng)D1Net將保留追究其法律責(zé)任的權(quán)利。








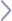






 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號